大家好,我是金威 (JIN V),来自天算AI科技研发实验室 (Natural Algorithm AI R&D Lab)。我们实验室致力于“探索自然算法,构建普惠AGI”,进行独立研发并以非营利模式运营。今天,我非常激动地与大家分享我们近期在AIGC(人工智能生成内容)领域的一个小实验:利用大型语言模型(LLM)结合LoRA微调技术,对gpt2模型进行改造,使其能够预测车辆的未来行驶轨迹,并初步探索如何让这些预测带上“物理常识”的印记。

“天算AI”的愿景与本次实验的初衷
在天算AI,我们的核心研究方向覆盖AIGC、AGI(通用人工智能)以及至关重要的AI安全(ASIAI Safety)。我们坚信,真正的通用人工智能不仅需要强大的模式识别和生成能力,更需要对现实世界基本规则的深刻理解。物理规律,正是构成我们所处宇宙基石的核心要素之一。
本次实验的初衷,便是探索如何将LLM这种以数据驱动见长的技术,与具有普适性的物理常识相结合,并将其应用于自动驾驶领域中的一个关键子任务——车辆轨迹预测。我们希望通过这样的尝试,为构建更智能、更可靠、也更安全的AI系统积累实践经验。
微调过程简述:用LoRA为GPT-2注入“轨迹DNA”
为了在有限的计算资源下快速验证核心思路,我们的实验流程设计力求简洁与高效:
- 基础模型选型: 我们选择了经典的
gpt2作为基础语言模型。尽管它并非最新的模型,但其清晰的Transformer架构和丰富的社区资源使其成为原型验证的理想选择。 - 数据“智”造——赋予数据物理意义: 高质量数据是成功的关键。由于缺乏完全符合我们实验设想的开源标注数据集,我们编写脚本综合生成了训练和测试数据。这些数据并非简单的随机数字序列,而是基于简化的二维物理模型(匀速直线运动和匀加速直线运动)生成,确保了每条轨迹在理想条件下符合基本的运动学规律。轨迹数据被编码为文本格式,例如:
历史: x1,y1,vx1,vy1; x2,y2,vx2,vy2; 预测: x3,y3,vx3,vy3; x4,y4,vx4,vy4;,其中时间步长dt设定为0.1秒。本次实验中,我们使用了约300条轨迹样本进行训练。 - 高效微调技术:LoRA大显身手。为了在不重新训练整个庞大模型的前提下让
gpt2适应轨迹预测这一新任务,我们采用了LoRA (Low-Rank Adaptation)技术。具体而言,我们主要对gpt2模型中的注意力权重(c_attn)部分添加了LoRA层,其秩(r)设置为8,alpha设置为16。 - 训练执行: 整个微调过程在Google Colab提供的T4 GPU上完成。模型共进行了5个epoch的训练,批处理大小(batch size)为4,学习率(learning rate)设置为3e-4。训练的目标是让模型学会根据输入的一系列历史轨迹点(包含位置x, y和速度vx, vy),准确地续写生成未来若干时间步的轨迹点。
成果评估:数字背后的洞察
模型微调完成后,我们在一个包含50条独立样本的测试集上进行了细致的评估。我们不仅关注了传统的位移误差指标,也特别考察了模型预测的物理一致性。
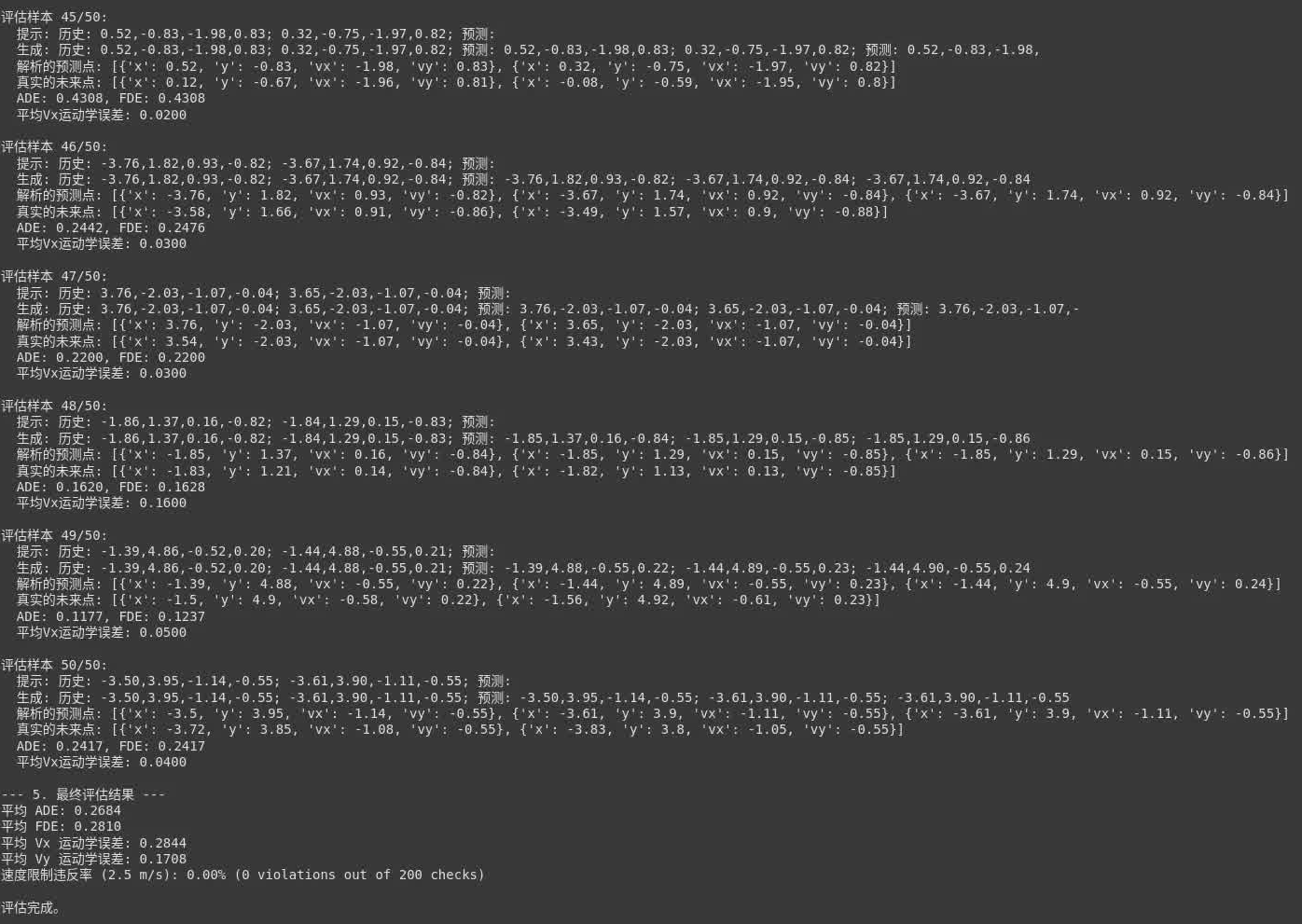
图1: 部分测试样本的预测详情及最终评估指标汇总
- 位移误差——“准不准”:
- 从图1的评估结果汇总(最后几行)可以看到:
- 平均位移误差 (ADE):
0.2684米。 这代表在每个预测时间步上,模型预测的位置与真实位置平均相差约0.27米。 - 最终位移误差 (FDE):
0.2810米。 这衡量的是整个预测时域结束时,预测终点与真实终点的差距。 - 解读: 对于一个基于小型LLM、小规模数据和短时间训练的实验性模型,这个准确度水平尚在可接受范围,表明模型确实从数据中学习到了基本的运动趋势。然而,我们也观察到,在某些特定样本上,误差会显著增大,这提示了模型在特定场景下的泛化能力仍有待提升。
- 运动学一致性——“讲不讲道理”:
- Vx误差 (X轴速度):
0.2844m/s - Vy误差 (Y轴速度):
0.1708m/s - 解读: 这两个指标衡量的是模型直接预测的速度分量,与其根据预测出的位置序列反推出来的速度分量(即
(pos_next - pos_curr) / dt)之间的一致性。数值越小,说明模型对“速度是位移对时间的导数”这一基本运动学关系的理解越好。当前的误差值说明,虽然模型能够分别预测速度和位置,但这两者之间的内在物理关联有时还不够紧密和精确。
- Vx误差 (X轴速度):
- 动力学约束——“守不守规矩”:
- 速度限制违反率 (V_max = 2.5 m/s):
0.00% - 解读: 这是一个非常令人鼓舞的结果!模型生成的所有轨迹点的速度值均未超过我们设定的2.5 m/s的上限。这很大程度上归功于训练数据本身遵循了这一隐性约束,模型成功地学习并复现了这一点,显示出其对数据分布中固有边界的学习能力。
- 速度限制违反率 (V_max = 2.5 m/s):
- 定性观察——“像不像话”:
- 从图1中逐条样本的详细输出可以看到,模型生成的文本格式基本符合预期。但偶尔会出现预测点数略多于请求数量的情况,或者在序列末尾附加一些无意义的、类似“噪声”的字符片段。这提示我们需要在序列生成的结束控制(例如,更有效地使用EOS token)以及输出的后处理解析方面做得更加精细和鲁棒。
可视化我们的探索:系统流程与交互体验
为了更直观地理解整个系统的概念和运作流程,我绘制了一张简化的流程/知识图谱:
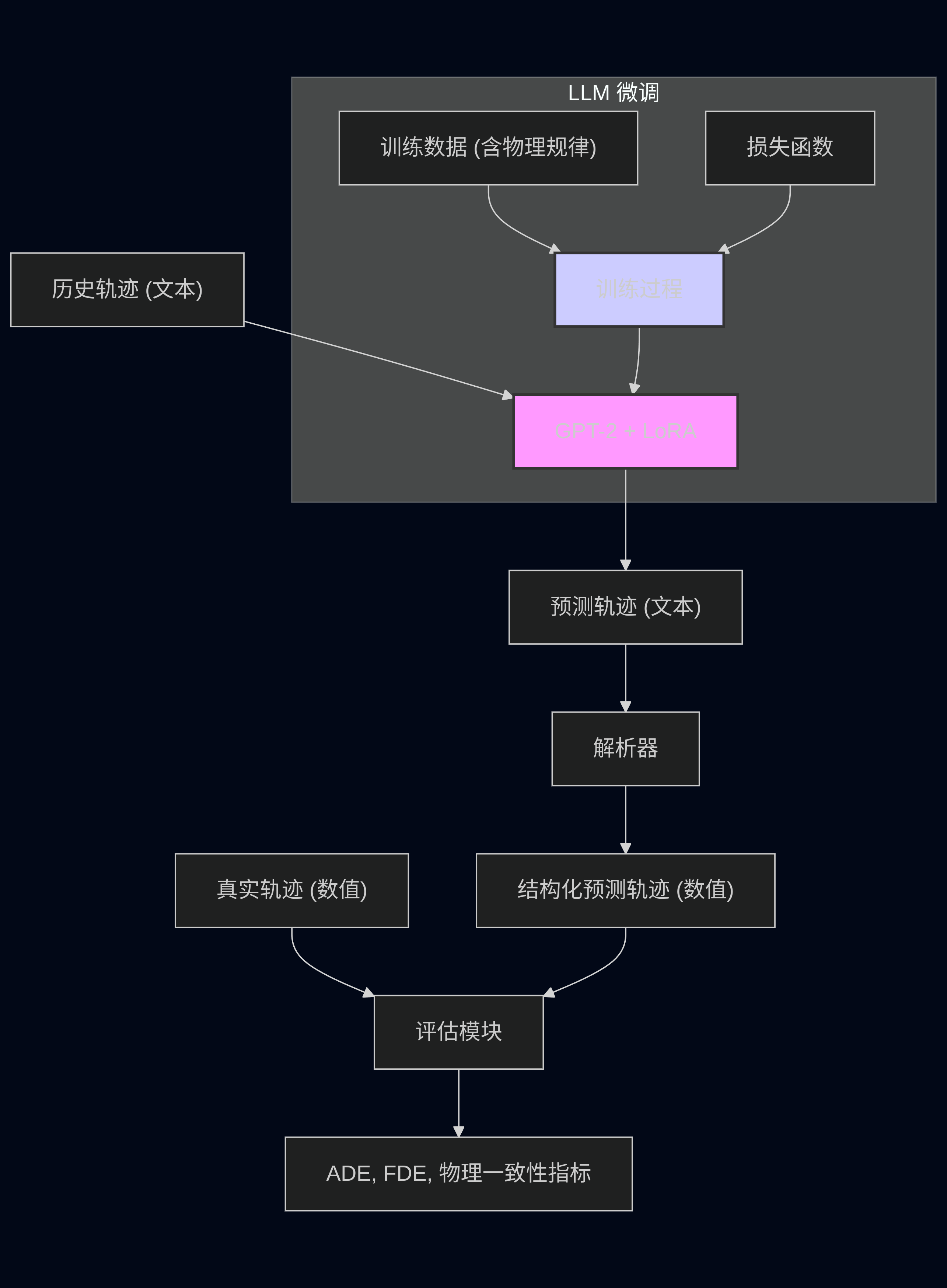
图2: LLM微调及轨迹预测与评估的整体流程图
(图2简要展示了从历史轨迹文本输入,经过GPT-2+LoRA模型处理,生成预测轨迹文本,再通过解析器转换为结构化数据,并最终与真实轨迹进行对比评估的完整闭环。)
同时,为了方便大家能够交互式地体验这个模型的能力,我基于Gradio框架搭建了一个简单的在线测试页面,并部署在Hugging Face Spaces上:
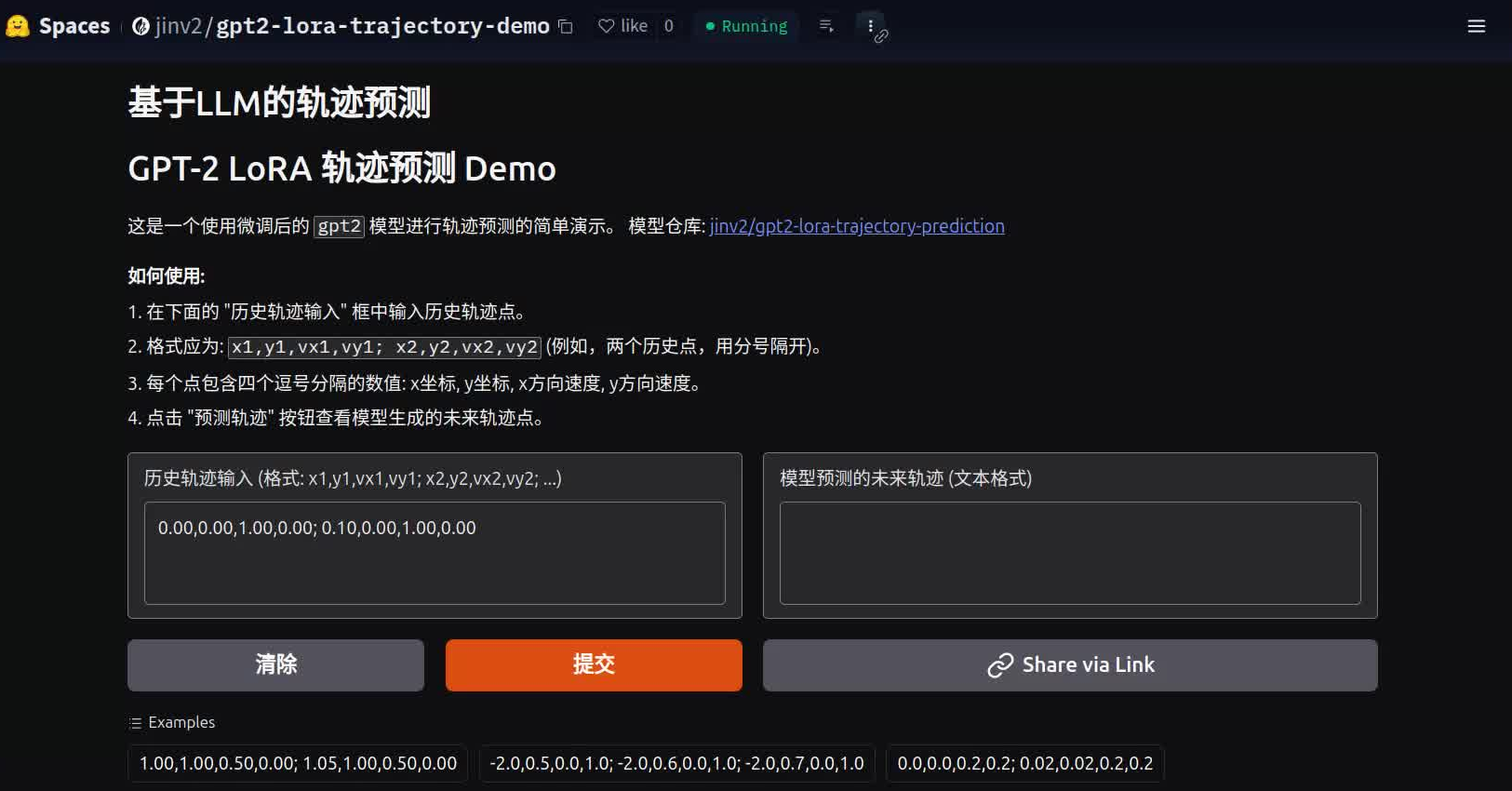
图3: Gradio在线轨迹预测演示页面截图
在线体验地址: jinv2/gpt2-lora-trajectory-demo on Hugging Face Spaces
开源与共享:我们的模型在Hugging Face
天算AI实验室相信开源的力量是推动技术进步的重要引擎。本次实验的所有核心成果,包括微调后的LoRA适配器权重、分词器配置文件以及详细的使用说明和评估细节,都已完整发布在Hugging Face Model Hub上:
我们热烈欢迎社区的朋友们访问、下载、使用我们的模型,并提出宝贵的反馈、建议或进行二次开发。
“天算AI”的持续探索与非营利承诺
在天算AI科技研发实验室,我们不仅仅进行此类具体应用的技术探索。我们目前已积累了包括5万字原创诗文、7000分钟原创AI生成交响乐、9000部原创AI短视频在内的多样化数字资产,并已独立研发了16项AI技术产品和10个针对特定垂直领域的天算AI大语言模型。本次轨迹预测的尝试,只是我们众多探索中的一小步。
我们始终坚持“探索自然算法,构建普惠AGI”的核心理念,进行完全独立的研发工作,并以非营利模式运营。我们深信,AI安全(ASIAI Safety)的考量必须与AGI技术的发展齐头并进,缺一不可。
我们热忱欢迎各界朋友、学术机构和有远见的企业与我们建立联系,无论是资金方面的慷慨资助、技术层面的深度共建,还是仅仅是思想上的碰撞与交流,我们都非常期待。
- 官方博客: jinv2.github.io
- 微信/联系方式: 15632151615
结语与未来展望
将大型语言模型(LLM)应用于具有强物理约束的现实世界问题,无疑是一个充满挑战但也极具潜力的前沿方向。这次基于gpt2和LoRA的轨迹预测实验,虽然只是一个初步的探索,但它有力地验证了LLM在学习和生成结构化时序数据方面的潜在能力,并为未来如何更深度地融合领域知识(如物理学、控制论等)指明了可能的路径。
未来的工作可以包括但不限于:
- 引入更复杂的、可微的物理方程作为显式约束,直接集成到模型的损失函数或网络结构中,以期获得更强的物理一致性。
- 使用更大规模、更丰富多样、更接近真实驾驶场景的数据集进行训练和评估。
- 探索多模态输入(例如,结合视觉图像、LiDAR点云信息)与轨迹预测的融合。
- 对模型的可解释性进行更深入的研究,理解其决策过程。
感谢您的阅读!期待与您在探索人工智能的道路上继续交流与学习。
版权与许可:
© 2024 天算AI科技研发实验室 (Natural Algorithm AI R&D Lab) - 金威 (JIN V)
本项目所涉及的开源模型(特指发布在Hugging Face上的 jinv2/gpt2-lora-trajectory-prediction)根据 Apache License 2.0 许可证授权。